MongoDB 数据库高级进阶 - 集群和安全
配套资料:
https://pan.baidu.com/s/18au42FIhSNrXY9p7MbmNbg提取码:29ad感谢 B 站用户
冷鸟丨会飞分享
课程目标
- MongoDB 的副本集:操作、主要概念、故障转移、选举规则
- MongoDB 的分片集群:概念、优点、操作、分片策略、故障转移
- MongoDB 的安全认证
1. MongoDB 副本集 - Replica Sets
1.1 简介
MongoDB 中的副本集(Replica Set)是一组维护相同数据集的 mongod 服务。 副本集可提供冗余和高可用性,是所有生产部署的基础。
也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就是用多台机器进行同一数据的异步同步,从而使多台机器拥有同一数据的多个副本,并且当主库当掉时在不需要用户干预的情况下自动切换其他备份服务器做主库。而且还可以利用副本服务器做只读服务器,实现读写分离,提高负载。
冗余和数据可用性
复制提供冗余并提高数据可用性。 通过在不同数据库服务器上提供多个数据副本,复制可提供一定级别的容错功能,以防止丢失单个数据库服务器。
在某些情况下,复制可以提供增加的读取性能,因为客户端可以将读取操作发送到不同的服务上, 在不同数据中心维护数据副本可以增加分布式应用程序的数据位置和可用性。 还可以为专用目的维护其他副本,例如灾难恢复,报告或备份。
MongoDB 中的复制
副本集是一组维护相同数据集的 mongod 实例。 副本集包含多个数据承载节点和可选的一个仲裁节点。 在承载数据的节点中,一个且仅一个成员被视为主节点,而其他节点被视为次要(从)节点。
主节点接收所有写操作。 副本集只能有一个主要能够确认具有 {w:"most"} 写入关注的写入; 虽然在某些情况下,另一个 mongod 实例可能暂时认为自己也是主要的。主要记录其操作日志中的数据集的所有 更改,即 oplog。
辅助(副本)节点复制主节点的oplog并将操作应用于其数据集,以使辅助节点的数据集反映主节点的数据 集。 如果主要人员不在,则符合条件的中学将举行选举以选出新的主要人员。
主从复制和副本集区别
主从集群和副本集最大的区别就是副本集没有固定的”主节点”;整个集群会选出一个”主节点”,当其挂掉后,又在剩下的从节点中选中其他节点为主节点,副本集总有一个活跃点 (主、primary) 和一个或多个备份节点 (从、secondary)
1.2 副本集的三个角色
副本集有两种类型三种角色
两种类型:
- 主节点(Primary)类型:数据操作的主要连接点,可读写
- 次要(辅助、从)节点(Secondary)类型:数据冗余备份节点,可以读或选举
三种角色:
- 主要成员(Primary):主要接收所有写操作。就是主节点
- 副本成员(Replicate):从主节点通过复制操作以维护相同的数据集,即备份数据,不可写操作,但可以读操作(但需要配置)。是默认的一种从节点类型
- 仲裁者(Arbiter):不保留任何数据的副本,只具有投票选举作用。当然也可以将仲裁服务器维护为副本集的一部分,即副本成员同时也可以是仲裁者。也是一种从节点类型。
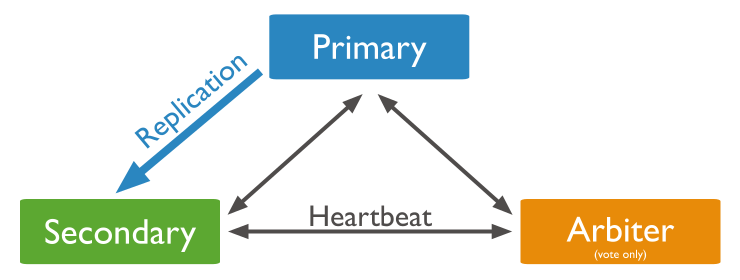
关于仲裁者的额外说明:
您可以将额外的 mongod 实例添加到副本集作为仲裁者。 仲裁者不维护数据集。 仲裁者的目的是通过响应其他副本集成员的心跳和选举请求来维护副本集中的仲裁。 因为它们不存储数据集,所以仲裁器可以是提供副本集仲裁功能的好方法,其资源成本比具有数据集的全功能副本集成员更便宜。
如果您的副本集具有偶数个成员,请添加仲裁者以获得主要选举中的大多数投票。 仲裁者不需要专用 硬件。
仲裁者将永远是仲裁者,而主要人员可能会退出并成为次要人员,而次要人员可能成为选举期间的主要人员。
如果你的副本+主节点的个数是偶数,建议加一个仲裁者,形成奇数,容易满足大多数的投票。
如果你的副本+主节点的个数是奇数,可以不加仲裁者。
说人话就是 Paxos 协议算法, 建议阅读
1.3 动手实现一个副本集
1.3.1 创建节点
使用一个主节点, 一个副节点, 一个仲裁节点
- 用端口号区分不同的节点
- 副本集名称都是
myrs
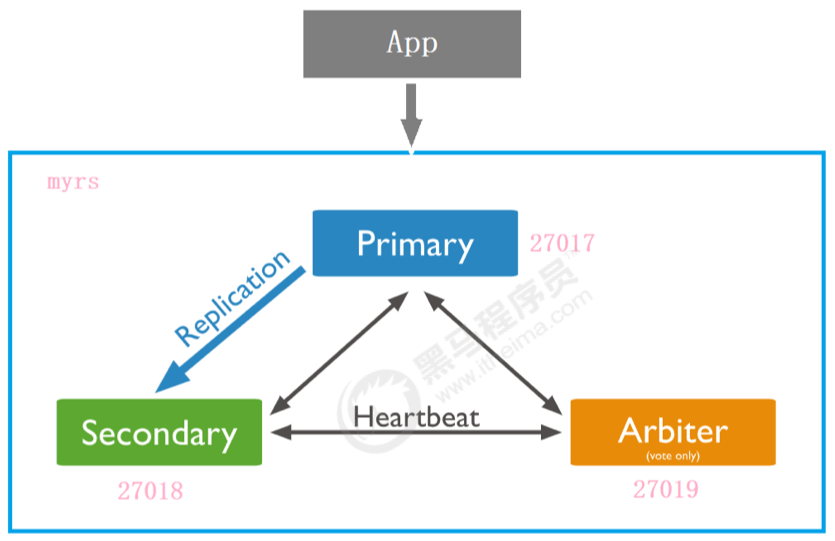
主节点 (PRIMARY), 副节点 (SECONDARY), 以及仲裁节点 (ARBITER) 的创建过程详见配套文档
1.3.2 初始化配置副本集和主节点
使用客户端命令连接任意一个节点,但这里尽量要连接主节点 (27017节点)
$ /usr/local/mongodb/bin/mongo --host=180.76.159.126 --port=27017
连接上之后,很多命令无法使用, 比如 show dbs 等,必须初始化副本集才行
初始化新的副本集
# example, `configuration` is optional
# rs.initiate(configuration)
$ rs.initiate()
{
"info2" : "no configuration specified. Using a default configuration for the set",
"me" : "<ip_address>:27017",
"ok" : 1,
"operationTime" : Timestamp(1565760476, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1565760476, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
myrs:SECONDARY> <hit enter>
myrs:PRIMARY>
ok的值为1, 说明创建成功- 命令行提示符发生变化,变成了一个从节点角色,此时默认不能读写。稍等片刻,回车,变成主节 点。
1.3.3 查看配置
# configuration - optional
$ rs.conf(configuration)
myrs:PRIMARY> rs.conf()
{
"_id" : "myrs",
"version" : 1,
"protocolVersion" : NumberLong(1),
"writeConcernMajorityJournalDefault" : true,
"members" : [{
"_id" : 0,
"host" : "180.76.159.126:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {},
"slaveDelay" : NumberLong(0),
"votes" : 1
}],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"catchUpTakeoverDelayMillis" : 30000,
"getLastErrorModes" : {},
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
},
"replicaSetId" : ObjectId("5d539bdcd6a308e600d126bb")
}
}
"_id" : "myrs":副本集的配置数据存储的主键值,默认就是副本集的名字"members":副本集成员数组,此时只有一个:"host" : "180.76.159.126:27017",该成员不是仲裁节点:"arbiterOnly" : false,优先级(权重值):"priority" : 1"settings":副本集的参数配置。
1.3.4 查看副本集状态
返回包含状态信息的文档。此输出使用从副本集的其他成员发送的心跳包中获得的数据反映副本集的当 前状态
$ rs.status()
1.3.5 添加副本节点以及仲裁节点
在主节点添加从节点,将其他成员加入到副本集
$ rs.add(host, arbiterOnly)
添加一个仲裁节点到副本集
$ rs.addArb(host)
1.4 副本集的数据读写操作
副本节点 (SECONDARY) 默认不能 read , 更不可能 write 数据, 需要
$ rs.slaveOk()
myrs:SECONDARY> show dbs;
"errmsg" : "not master and slaveOk=false",
# 非主节点同时 slaveOk=false 无法读写
数据会自动同步, 但是会有延迟
仲裁者节点, 不存放任何数据 -> rs.slaveOk() 也看不到数据
1.5 主节点的选举原则
MongoDB在副本集中,会自动进行主节点的选举,主节点选举的触发条件
- 主节点故障
- 主节点网络不可达 (默认心跳信息为 10 秒)
- 人工干预
rs.stepDown(600)
一旦触发选举,就要根据一定规则来选主节点
选举规则是根据票数来决定谁获胜
- 票数最高,且获得了“大多数”成员的投票支持的节点获胜。
- “大多数”的定义为:假设复制集内投票成员数量为N,则大多数为 N/2 + 1。例如:3个投票成员, 则大多数的值是2。当复制集内存活成员数量不足大多数时,整个复制集将无法选举出Primary, 复制集将无法提供写服务,处于只读状态。
- 若票数相同,且都获得了“大多数”成员的投票支持的,数据新的节点获胜。
- 数据的新旧是通过操作日志 oplog 来对比的。
在获得票数的时候,优先级(priority)参数影响重大。
可以通过设置优先级(priority)来设置额外票数。优先级即权重,取值为0-1000,相当于可额外增加 0-1000的票数,优先级的值越大,就越可能获得多数成员的投票(votes)数。指定较高的值可使成员 更有资格成为主要成员,更低的值可使成员更不符合条件。
默认情况下,优先级的值是 1
1.6 故障测试
1.6.1 副本节点故障测试
关闭 27018 副本节点
-
主节点和仲裁节点对
27018的心跳失败。因为主节点还在,因此,没有触发投票选举。 -
如果此时,在主节点写入数据。再启动从节点,会发现,主节点写入的数据,会自动同步给从节点。
1.6.2 主节点故障测试
关闭27017节点
- 从节点和仲裁节点对27017的心跳失败,当失败超过10秒,此时因为没有主节点了,会自动发起投票。
- 而副本节点只有27018,因此,候选人只有一个就是27018,开始投票。
- 27019向27018投了一票,27018本身自带一票,因此共两票,超过了“大多数”
- 27019是仲裁节点,没有选举权,27018不向其投票,其票数是0.
最终结果,27018成为主节点。具备读写功能。 在27018写入数据查看。
1.6.3 仲裁节点和主节点故障
先关掉仲裁节点27019, 关掉现在的主节点27018 登录27017后
- 27017仍然是从节点,副本集中没有主节点了,导致此时,副本集是只读状态, 无法写入。
- 为啥不选举了?
- 因为27017的票数,没有获得大多数,即没有大于等于2,它只有默认的一票(优先级 是1)
- 如果要触发选举,随便加入一个成员即可。
- 如果只加入27019仲裁节点成员,则主节点一定是27017,因为没得选了,仲裁节点不参与选举, 但参与投票
- 如果只加入27018节点,会发起选举。因为27017和27018都是两票,则按照谁数据新,谁当主节点。
1.6.4 仲裁节点和从节点故障
先关掉仲裁节点 27019,关掉现在的副本节点 27018
10秒后,27017 主节点自动降级为副本节点。(服务降级)
副本集不可写数据了,已经故障了。
2. 分片集群 - Sharded Cluster
2.1 分片概念
分片 (sharding) 是一种跨多台机器分布数据的方法, MongoDB 使用分片来支持具有非常大的数据集和高吞吐量操作的部署。
换句话说:分片 (sharding) 是指将数据拆分,将其分散存在不同的机器上的过程。有时也用分区 (partitioning) 来表示这个概念。将数据分散到不同的机器上,不需要功能强大的大型计算机就可以储存更多的数据,处理更多的负载。
具有大型数据集或高吞吐量应用程序的数据库系统可以会挑战单个服务器的容量。例如,高查询率会耗尽服务器的 CPU 容量。工作集大小大于系统的 RAM 会强调磁盘驱动器的 I/O 容量。
有两种解决系统增长的方法:垂直扩展和水平扩展。
- 垂直扩展意味着增加单个服务器的容量,例如使用更强大的CPU,添加更多RAM或增加存储空间量。可 用技术的局限性可能会限制单个机器对于给定工作负载而言足够强大。此外基于云的提供商基于可用的硬件配置具有硬性上限。结果,垂直缩放有实际的最大值。
- 水平扩展意味着划分系统数据集并加载多个服务器,添加其他服务器以根据需要增加容量。虽然单个机器的总体速度或容量可能不高,但每台机器处理整个工作负载的子集,可能提供比单个高速大容量服务器更高的效率。扩展部署容量只需要根据需要添加额外的服务器,这可能比单个机器的高端硬件的总体 成本更低。权衡是基础架构和部署维护的复杂性增加。
MongoDB 支持通过分片进行水平扩展。
2.2 分片集群包含的组件
MongoDB 分片群集包含以下组件:
- 分片(存储):每个分片包含分片数据的子集。 每个分片都可以部署为副本集。
- mongos (路由):mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。
- config servers (”调度” 的配置):配置服务器存储群集的元数据和配置设置。 从MongoDB 3.4 开始,必须将配置服务器部署为副本集(CSRS)。

2.3 分片集群架构目标
两个分片节点副本集(3+3)+ 一个配置节点副本集(3)+ 两个路由节点(2),共
11个服务节点
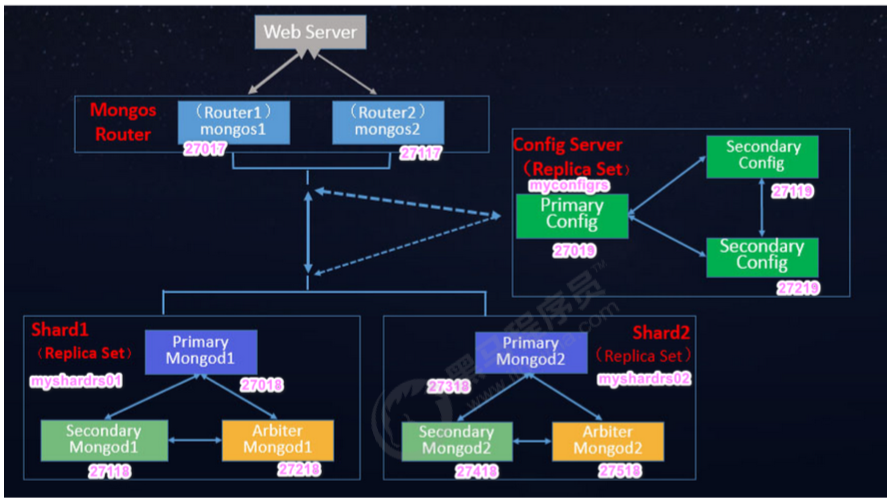
副本集的创建详见文档以及视频
添加分片
$ sh.addShard("IP:Port", "IP:Port", "IP:Port")
查看分片状态情况
$ sh.status()
如果添加分片失败,需要先手动移除分片,检查添加分片的信息的正确性后,再次添加分片。 移除分片:
$ use admin
$ db.runCommand( { removeShard: "myshardrs02" } )
- 如果只剩下最后一个 shard,是无法删除的
- 移除时会自动转移分片数据,需要一个时间过程
- 完成后,再次执行删除分片命令才能真正删除
开启分片功能
$ sh.enableSharding("articledb")
$ sh.enableSharding("库名")
$ sh.shardCollection("库名.集合名",{"key":1})
集合分片,使用 sh.shardCollection() 方法指定集合和分片键
$ sh.shardCollection(namespace, key, unique)
对集合进行分片时, 你需要选择一个 片键 (Shard Key) shard key 是每条记录都必须包含的, 且建立了索引的单个字段或复合字段, MongoDB按照片键将数据划分到不同的数据块中,并将数据块均衡地分布到所有分片中. 为了按照片键划分数据块, MongoDB使用基于哈希的分片方式(随机平均分配)或者基于范围的分片方式(数值大小分配) 。
用什么字段当片键都可以,如:nickname作为片键,但一定是必填字段。
分片策略(规则)
哈希策略
对于 基于哈希 的分片 , MongoDB计算一个字段的哈希值, 并用这个哈希值来创建数据块.
在使用基于哈希分片的系统中, 拥有”相近”片键的文档很可能不会存储在同一个数据块中, 因此数据的分离性更好一些.
范围策略
对于 基于范围 的分片 , MongoDB 按照片键的范围把数据分成不同部分. 假设有一个数字的片键 : 想象一个从负无穷到正无穷的直线,每一个片键的值都在直线上画了一个点. MongoDB把这条直线划分为更短的不重叠的片段, 并称之为数据块 ,每个数据块包含了片键在一定范围内的数据.
在使用片键做范围划分的系统中, 拥有”相近”片键的文档很可能存储在同一个数据块中, 因此也会存储在同一个分片中.
基于范围的分片方式与基于哈希的分片方式性能对比
基于范围的分片方式提供了更高效的范围查询, 给定一个片键的范围,分发路由可以很简单地确定哪个数 据块存储了请求需要的数据,并将请求转发到相应的分片中. 不过, 基于范围的分片会导致数据在不同分片上的不均衡,有时候,带来的消极作用会大于查询性能的积极作用. 比如, 如果片键所在的字段是线性增长的, 一定时间内的所有请求都会落到某个固定的数据块中, 最终导致分布在同一个分片中. 在这种情况下, 一小部分分片承载了集群大部分的数据,系统并不能很好地进行 扩展. 与此相比, 基于哈希的分片方式以范围查询性能的损失为代价, 保证了集群中数据的均衡.哈希值的随机性 使数据随机分布在每个数据块中, 因此也随机分布在不同分片中.但是也正由于随机性, 一个范围查询很难 确定应该请求哪些分片, 通常为了返回需要的结果,需要请求所有分片.
如无特殊情况,一般推荐使用 Hash Sharding. 而使用 _id 作为片键是一个不错的选择,因为它是必有的,你可以使用数据文档 _id 的哈希作为片键。 这个方案能够是的读和写都能够平均分布,并且它能够保证每个文档都有不同的片键所以数据块能够很 精细。 似乎还是不够完美,因为这样的话对多个文档的查询必将命中所有的分片。虽说如此,这也是一种比较 好的方案了。 理想化的 shard key 可以让 documents 均匀地在集群中分布
3. 安全认证
3.1 MongoDB的用户和角色权限简介
默认情况下,MongoDB实例启动运行时是没有启用用户访问权限控制的,也就是说,在实例本机服务 器上都可以随意连接到实例进行各种操作,MongoDB不会对连接客户端进行用户验证,这是非常危险 的。
mongodb官网上说,为了能保障mongodb的安全可以做以下几个步骤
- 使用新的端口,默认的 27017 端口如果一旦知道了 ip 就能连接上,不太安全
- 设置 mongodb 的网络环境,最好将 mongodb 部署到公司服务器内网,这样外网是访问不到的。公 司内部访问使用 vpn 等
- 开启安全认证。认证要同时设置服务器之间的内部认证方式,同时要设置客户端连接到集群的账号 密码认证方式。
为了强制开启用户访问控制(用户验证),则需要在MongoDB实例启动时使用选项 –auth 或在指定启动 配置文件中添加选项 auth=true
在开始之前需要了解一下概念
启用访问控制
- MongoDB使用的是基于角色的访问控制(Role-Based Access Control,RBAC)来管理用户对实例的访问。 通过对用户授予一个或多个角色来控制用户访问数据库资源的权限和数据库操作的权限,在对用户分配 角色之前,用户无法访问实例
- 在实例启动时添加选项 –auth 或指定启动配置文件中添加选项
auth=true
角色
在MongoDB中通过角色对用户授予相应数据库资源的操作权限,每个角色当中的权限可以显式指定, 也可以通过继承其他角色的权限,或者两都都存在的权限。
权限
权限由指定的数据库资源(resource)以及允许在指定资源上进行的操作(action)组成
-
资源(resource)包括:数据库、集合、部分集合和集群
-
操作(action)包括:对资源进行的增、删、改、查(CRUD)操作
在角色定义时可以包含一个或多个已存在的角色,新创建的角色会继承包含的角色所有的权限。在同一 个数据库中,新创建角色可以继承其他角色的权限,在 admin 数据库中创建的角色可以继承在其它任意 数据库中角色的权限。
# 查询所有角色权限(仅用户自定义角色)
$ db.runCommand({ rolesInfo: 1 })
# 查询所有角色权限(包含内置角色)
$ db.runCommand({ rolesInfo: 1, showBuiltinRoles: true })
# 查询当前数据库中的某角色的权限
$ db.runCommand({ rolesInfo: "<rolename>" })
# 查询其它数据库中指定的角色权限
$ db.runCommand({ rolesInfo: { role: "<rolename>", db: "<database>" } }
# 查询多个角色权限
$ db.runCommand({
rolesInfo: [
"<rolename>",
{
role: "<rolename>",
db: "<database>"
},
...
]
})
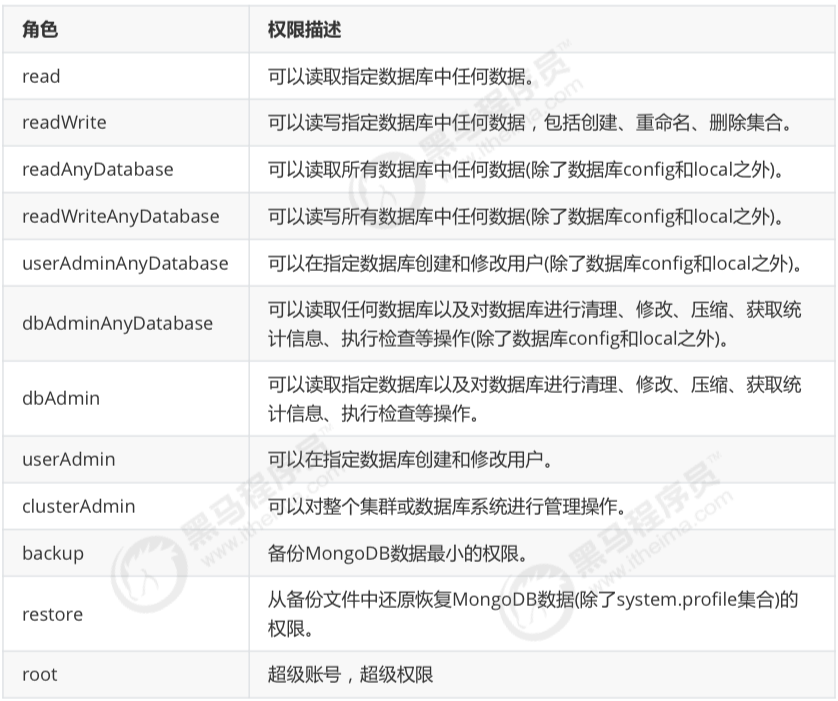
常用的内置角色:
- 数据库用户角色:read、readWrite
- 所有数据库用户角色:readAnyDatabase、readWriteAnyDatabase、 userAdminAnyDatabase、dbAdminAnyDatabase
- 数据库管理角色: dbAdmin、dbOwner、userAdmin
- 集群管理角色: clusterAdmin、clusterManager、clusterMonitor、hostManager
- 备份恢复角色: backup、restore
- 超级用户角色: root
- 内部角色: system
剩下的内容看文档吧 -.-!!
References
- https://www.bilibili.com/video/BV1bJ411x7mq
- 分布式一致性协议在 MongoDB 选举中的应用