Understanding Spark’s Design and Operation Principles
Overview of Spark
Spark is renowned for its exceptional processing speed.
- It leverages in-memory computing and adopts a cyclic data flow approach (where results from previous Reduce operations are used as inputs for subsequent MapReduce operations), significantly minimizing reliance on IO streams.
- While it aims to minimize disk usage, it may occasionally resort to disk operations, although it strives to keep them to a minimum.
- Its design is based on Directed Acyclic Graphs (DAGs) for efficient pipeline optimization.
Spark’s Runtime Architecture
Fundamental Concepts and Architectural Design of Spark
- RDD: Resilient Distributed Dataset. It represents a distributed in-memory dataset (employing a highly constrained shared-memory model).
- DAG: Describes the dependency relationships between RDDs.
- Executor: A process running on a worker node, responsible for executing tasks.
- Each process spawns multiple threads, with each thread handling relevant tasks.
- Application: A program developed using Spark.
- Task: The basic unit of work executed by an Executor.
- Job: Comprising multiple RDDs and various operations applied to them (RDD + operation).
- Stage: The primary scheduling unit of a job, consisting of multiple groups of tasks. Each group, known as a Stage or TaskSet, represents a set of tasks with no inter-task shuffle dependencies.
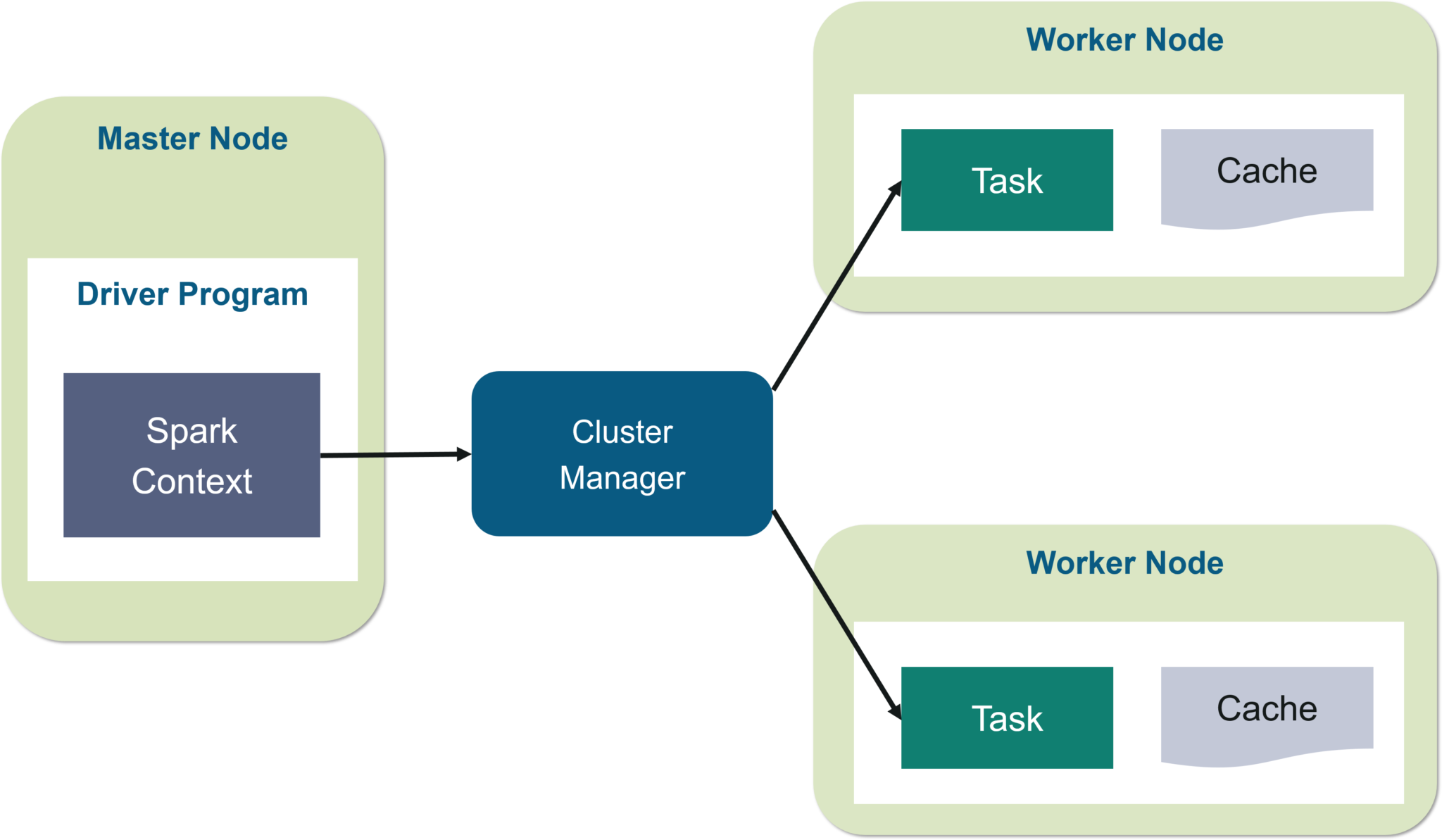
Driver Program: Task Control Node
The Cluster Manager is responsible for scheduling cluster resources such as CPU, memory, bandwidth, and more.
Spark provides its own built-in Cluster Manager, but it also supports integration with other systems like Hadoop YARN and Mesos.
The Driver Program requests resources from the Cluster Manager and initiates Executors on Worker Nodes. It then sends code and file data to the Worker Node, where threads spawned by Executors execute tasks. Finally, the execution results are sent back to the Driver Program.
Basic Workflow of Spark Execution
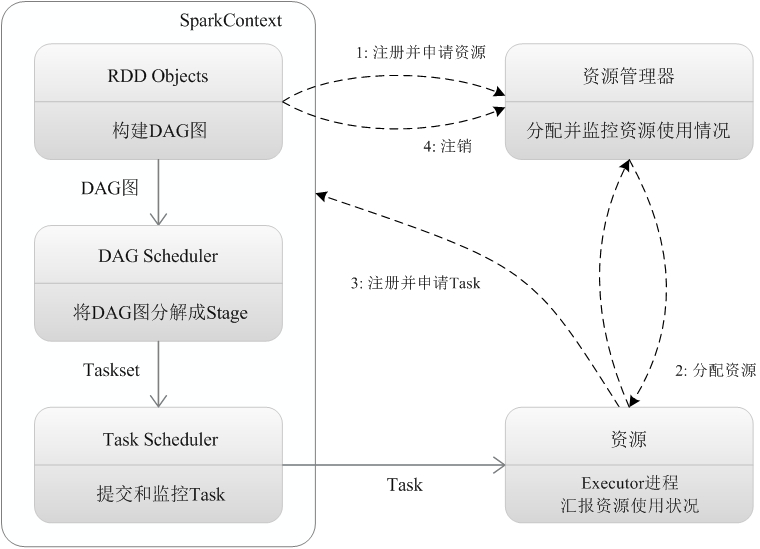
The Spark Context generates a Directed Acyclic Graph (DAG) based on the dependencies of your RDDs. Your code operates directly on this DAG. The DAG is then handed over to the DAG Scheduler, which parses it into multiple stages, each comprising several tasks.
Threads spawned by Executors request execution from the Task Scheduler, which is responsible for task distribution.
Computing Approaches Data
If machines A (with data), B, and C simultaneously request from the Task Scheduler, who gets the task?
The answer is A. The Task Scheduler checks if A has the data; if so, it assigns the task directly to A. Otherwise, it needs to transfer the data from A to another machine.
RDD Operation Principles
Hadoop is not suitable for iterative tasks because it stores intermediate data on disk, requiring subsequent tasks to reread the data from disk. The overhead of disk IO and serialization/deserialization is significant.
Different tasks can all be transformed into RDD transformations, ultimately forming DAG dependency relationships.
RDD: A distributed object fundamentally a read-only collection of partitioned records. If the data is extensive, it can be distributed across different machines, with each machine hosting a partition of the data, facilitating efficient parallel computation.
The term “highly restricted shared-memory model” for RDDs signifies:
- “Highly restricted”: Read-only; once generated, it cannot be altered.
- “Shared memory model”: Data sets generated in memory.
Types of RDD Operations
- Action: Actions perform actions on the RDD.
- Transformation: Transformations modify the RDD.
Both types of operations are coarse-grained modifications, capable of modifying the entire RDD at once.
They can only modify entire sets; unlike SQL, they cannot transform specific rows or columns.
RDD Execution Process
- RDDs are created by reading from external data sources.
- RDDs undergo a series of transformations, with each transformation generating a different RDD for the next operation.
- The final RDD undergoes an Action operation to transform and output it to an external data source.
Some Characteristics of RDDs
- Lazy Evaluation Mechanism
Transformation operations do not yield results immediately; they merely record the process/trajectory of transformation without actual computation. Computation is triggered only when it reaches an Action operation, such as .count().
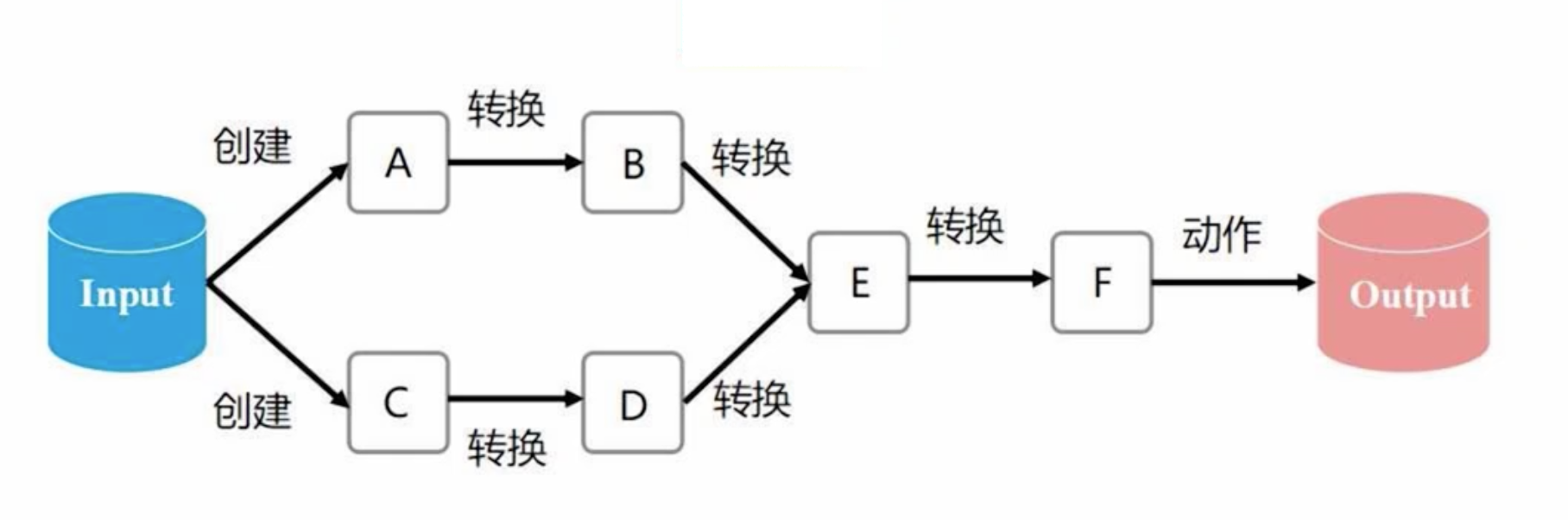
- Inherent Fault Tolerance
Spark possesses inherent fault tolerance, primarily due to the existence of lineage relationships during RDD transformations. In the diagram above, for example, B is derived from A, and E is derived from both B and D. If data recovery is necessary, retracing the lineage process is sufficient.
- Avoiding Unnecessary Serialization/Deserialization
Intermediate results of RDDs are persisted in memory, and RDD.cache() minimizes unnecessary disk I/O operations. Data transfer operations among multiple RDDs in memory are facilitated by RDD.cache().
Dependency Relationships and Stage Division of RDDs
Why divide a job into multiple stages?
- Narrow Dependency: No stage division, allowing for pipeline optimization.
- Wide Dependency: Division into multiple stages, preventing pipeline optimization.
The key distinction between wide and narrow dependencies lies in whether Shuffle occurs:
- Massive data transmission back and forth in the network.
- Data transmission between different nodes.
Wide Dependency vs. Narrow Dependency
- Narrow Dependency: Each parent RDD partition corresponds to one child RDD partition, or multiple parent RDD partitions correspond to one child RDD partition.
- Wide Dependency: One parent RDD partition corresponds to multiple child RDD partitions.
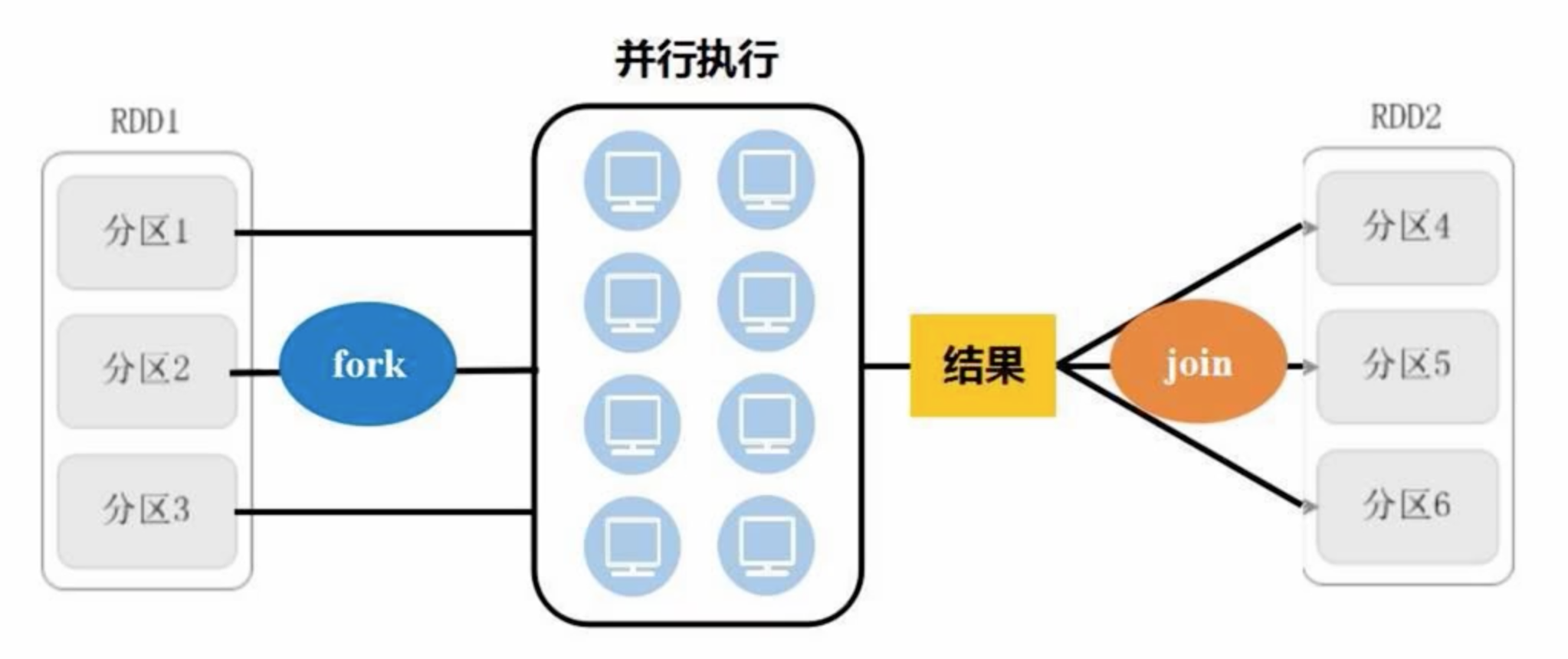
Optimization Principle: Fork/Join Mechanism
Avoiding meaningless waits, but Shuffle (wide dependency) always incurs disk writes.
Reverse Parsing of DAG
- Narrow Dependency: Continuously add stages.
- Wide Dependency: Generate different stages.
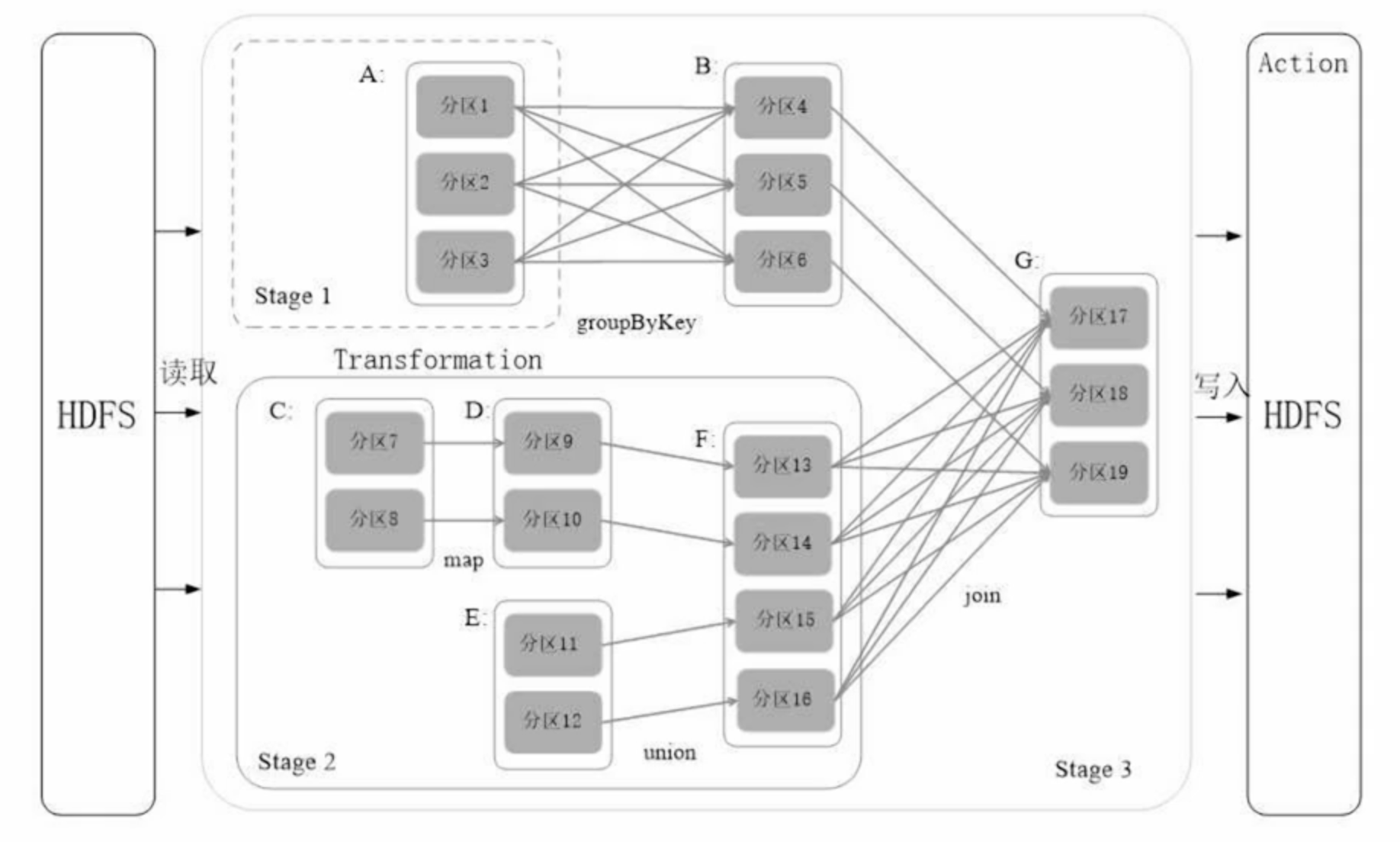
Execution of RDD
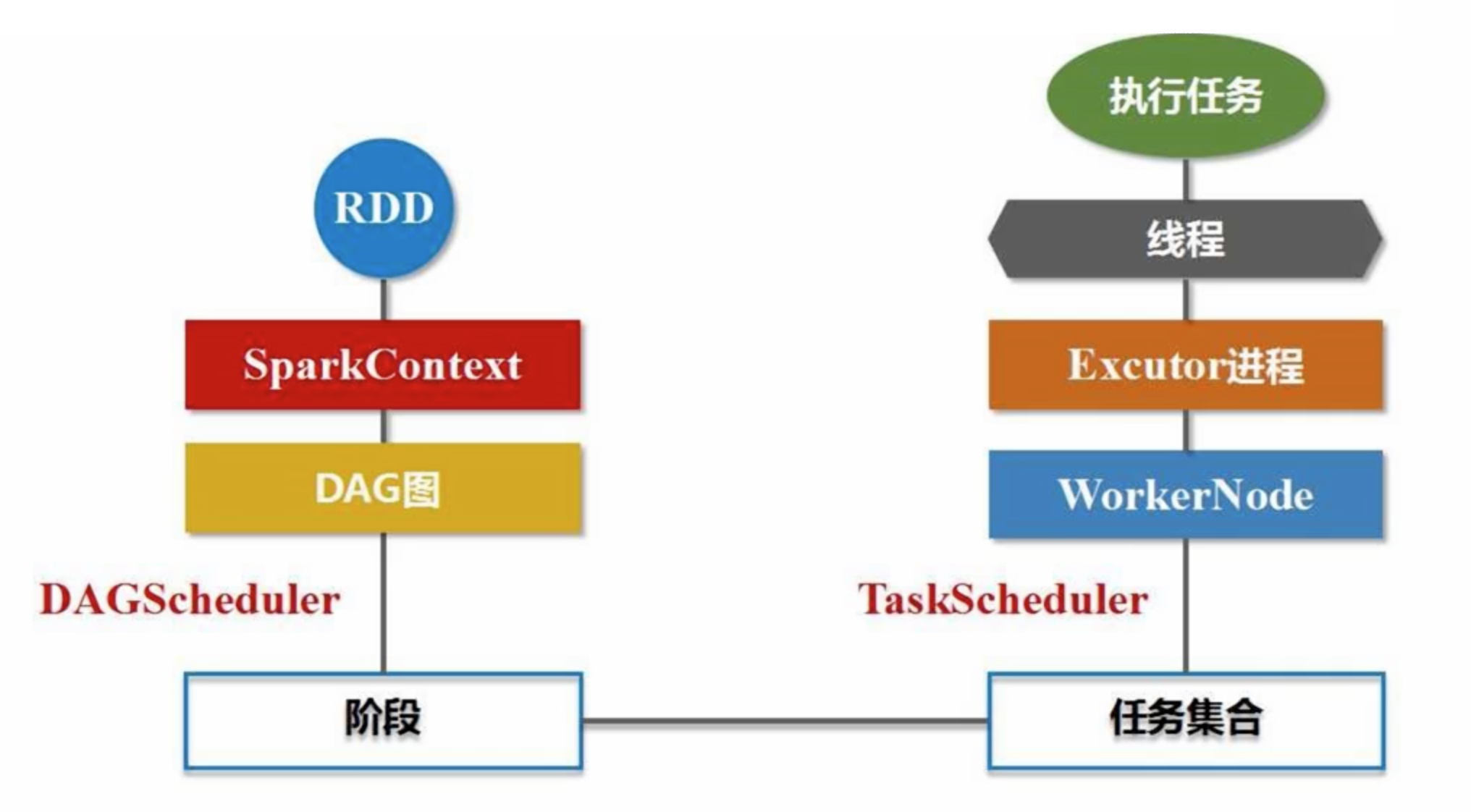
Using PySpark (Overview)
Example: WordCount
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("DemoApp")
sc = SparkContext(conf=conf)
logFile = "hdfs://master:9000/example.txt"
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
print("Lines containing 'a': {numAs}, lines containing 'b': {numBs}".format(numAs=numAs, numBs=numBs))