Spark Streaming
Spark Streaming
Spark Streaming 的基本原理是将实时输入数据流以时间片 (秒级) 为单位进行拆分, 然后经 Spark 引擎以类似批处理的方式处理每个时间片数据
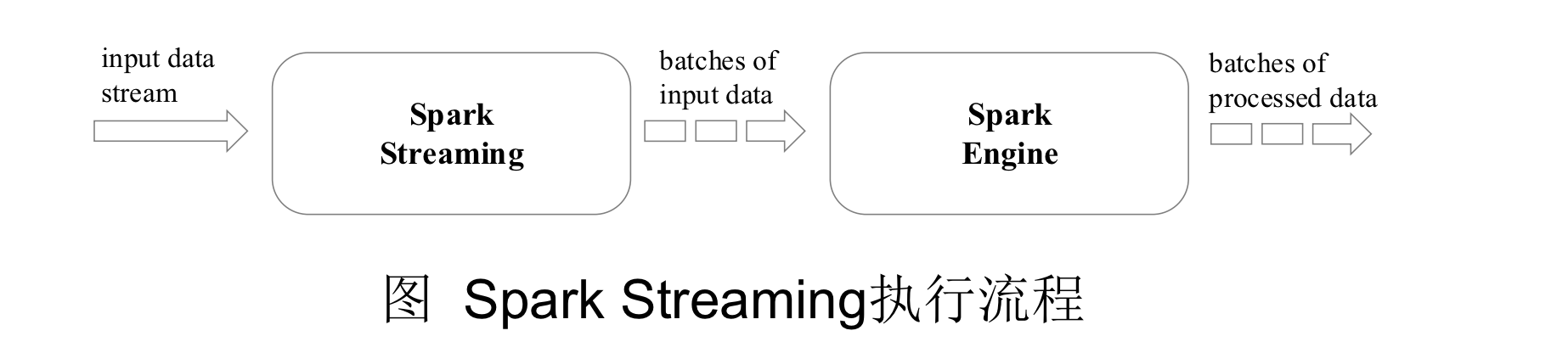
Spark 是以线程级别并行, 实时响应级别高
可以实现秒级响应, 变相实现高效的流计算
Spark Streaming 最主要的抽象是 DStream (Discretized Stream, 离散化数据流) , 表示连续不断的数据流. 在内部实现上, Spark Streaming 的输入数据按照时间片 (如 1 秒) 分成一段一段, 每一段数据转换为 Spark 中的 RDD, 这些分段就是 Dstream, 并且对 DStream 的操作都最终转变为对相应的 RDD 的操作
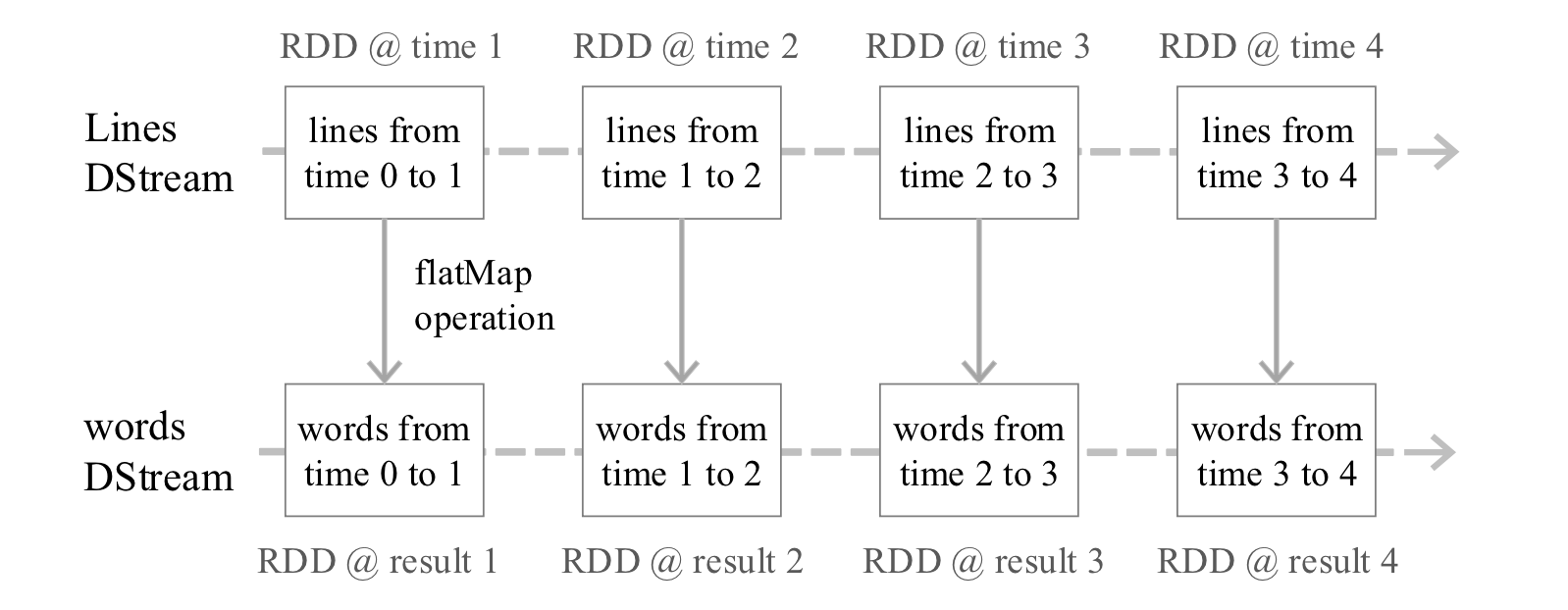
DStream 操作概述
Spark Streaming 工作机制
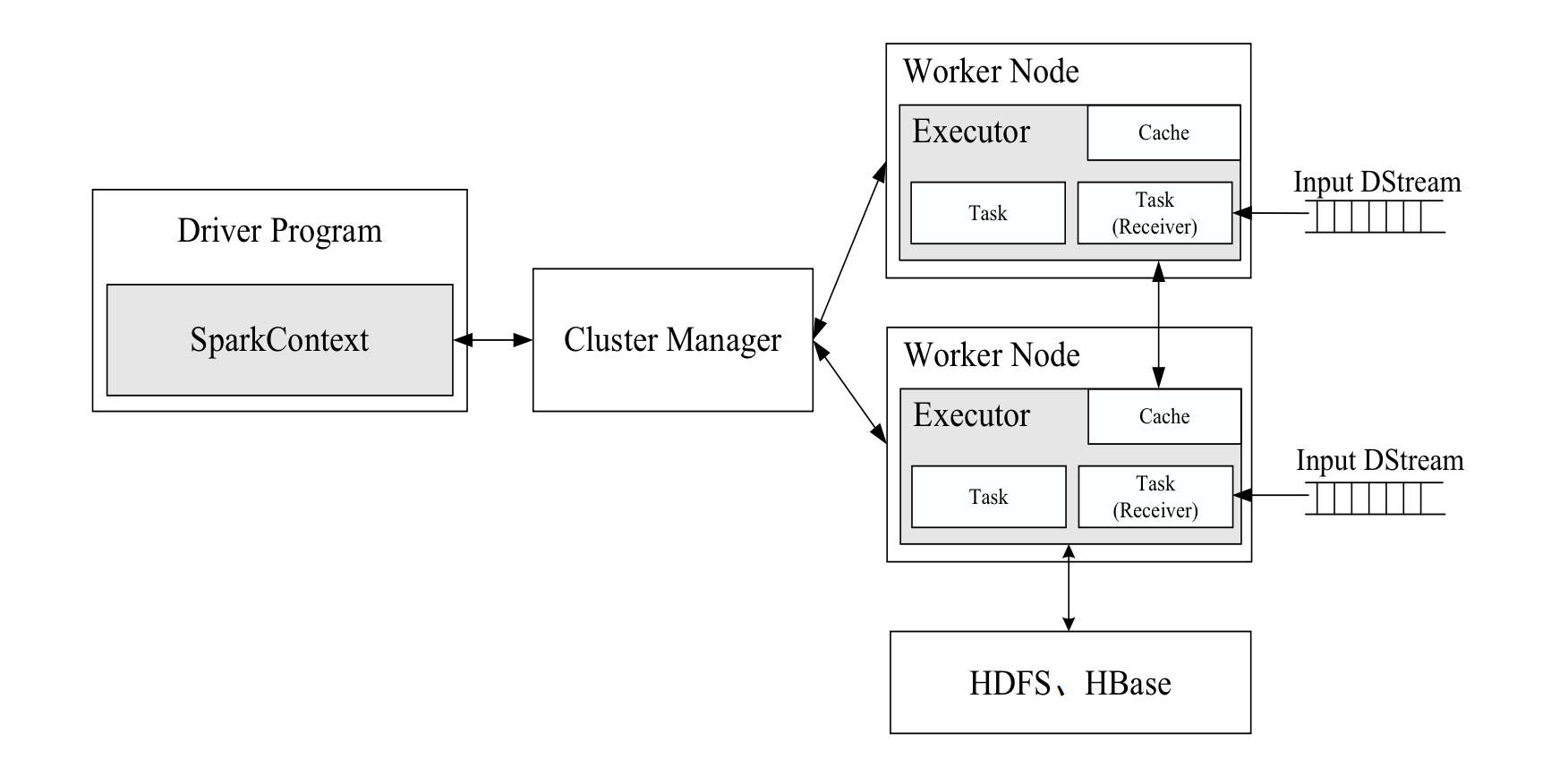
- 在 Spark Streaming 中, 会有一个组件 Receiver, 作为一个长期运行的 task 跑在一个 Executor 上
- 每个 Receiver 都会负责一个 input DStream (比如从文件中读取数据的文件流, 比如套接字流, 或者从 Kafka 中读取的一个输入流等等)
- Spark Streaming 通过 input DStream 与外部数据源进行连接, 读取相关数据
Every input DStream (except file stream) is associated with a Receiver (Scala doc, Java doc) object which receives the data from a source and stores it in Spark’s memory for processing. {:.info}
Points to remember:
- When running a Spark Streaming program locally, do not use
"local"or"local[1]"as the master URL. Either of these means that only one thread will be used for running tasks locally. If you are using an input DStream based on a receiver (e.g. sockets, Kafka, etc.), then the single thread will be used to run the receiver, leaving no thread for processing the received data. Hence, when running locally, always use"local[n]"as the master URL, wheren > number of receivers to run(see Spark Properties for information on how to set the master). - Extending the logic to running on a cluster, the number of cores allocated to the Spark Streaming application must be more than the number of receivers. Otherwise the system will receive data, but not be able to process it.
Spark Streaming 程序的基本步骤
编写 Spark Streaming 程序的基本步骤是:
- 通过创建输入 DStream 来定义输入源
- 通过对 DStream 应用转换操作和输出操作来定义流计算
- 用
streamingContext.start()来开始接收数据和处理流程 - 通过
streamingContext.awaitTermination()方法来等待处理结束 (手动结束或因为错误而结束) - 可以通过
streamingContext.stop()来手动结束流计算进程
创建 StreamingContext 对象
-
如果要运行一个 Spark Streaming 程序, 就需要首先生成一个 StreamingContext 对象, 它是 Spark Streaming 程序的主入口
- 可以从一个 SparkConf 对象创建一个 StreamingContext 对象.
- 在 pyspark 中的创建方法:进入 pyspark 以后, 就已经获得了一个默认的 SparkConext 对象, 也就是 sc. 因此, 可以采用如下方式来创建 StreamingContext 对象:
# pyspark interactive terminal
>>> from pyspark.streaming import StreamingContext
# sc 是自动生成时 SparkContext 对象实例
>>> ssc = StreamingContext(sc, 1)
如果是编写一个独立的 Spark Streaming 程序, 而不是在 pyspark 中运行, 则需要通过如下方式创建 StreamingContext 对象
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
conf = SparkConf()
conf.setAppName('TestDStream')
conf.setMaster('local[2]')
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 1)
基本输入源
文件流
1. 在 pyspark 中创建文件流
$ cd /usr/local/spark/mycode
$ mkdir streaming
$ cd streaming
$ mkdir logfile
$ cd logfile
进入 pyspark 创建文件流. 请另外打开一个终端窗口, 启动进入 pyspark
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc, 10)
lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile')
words = lines.flatMap(lambda line: line.split(' '))
wordCounts = words.map(lambda x :(x,1)).reduceByKey(lambda a,b:a+b)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
2. 采用独立应用程序方式创建文件流
$ cd /usr/local/spark/mycode
$ cd streaming
$ cd logfile
$ vim FileStreaming.py
#!/usr/bin/env python3
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
conf = SparkConf()
conf.setAppName('TestDStream')
conf.setMaster('local[2]')
sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 10)
lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile')
words = lines.flatMap(lambda line: line.split(' '))
wordCounts = words.map(lambda x : (x,1)).reduceByKey(lambda a,b:a+b)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
运行代码
$ cd /usr/local/spark/mycode/streaming/logfile/
$ /usr/local/spark/bin/spark-submit FileStreaming.py
套接字流
Spark Streaming 可以通过 Socket 端口监听并接收数据, 然后进行相应处理
$ cd /usr/local/spark/mycode
$ mkdir streaming # 如果已经存在该目录, 则不用创建
$ cd streaming
$ mkdir socket
$ cd socket
$ vim NetworkWordCount.py
#!/usr/bin/env python3
from __future__ import print_function
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import sys
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: NetworkWordCount.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingNetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
RDD 队列流
- 在调试 Spark Streaming 应用程序的时候, 我们可以使用
streamingContext.queueStream(queueOfRDD)创建基于 RDD 队列的 DStream - 新建一个
RDDQueueStream.py代码文件, 功能是:每隔 1 秒创建一个 RDD, Streaming 每隔 2 秒就对数据进行处理
RDDQueueStream.py
#!/usr/bin/env python3
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
sc = SparkContext(appName="PythonStreamingQueueStream")
ssc = StreamingContext(sc, 2)
# 创建一个队列, 通过该队列可以把 RDD 推给一个 RDD 队列流
rddQueue = []
for i in range(5):
rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)]
time.sleep(1)
# 创建一个 RDD 队列流
inputStream = ssc.queueStream(rddQueue)
mappedStream = inputStream.map(lambda x: (x % 10, 1))
reducedStream = mappedStream.reduceByKey(lambda a, b: a + b)
reducedStream.pprint()
ssc.start()
ssc.stop(stopSparkContext=True, stopGraceFully=True)
运行
$ cd /usr/local/spark/mycode/streaming/rddqueue
$ /usr/local/spark/bin/spark-submit RDDQueueStream.py
Kafka 作为数据源
KafkaWordCount.py
#!/usr/bin/env python3
from __future__ import print_function
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
import sys
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: KafkaWordCount.py <zk> <topic>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingKafkaWordCount")
ssc = StreamingContext(sc, 1)
zkQuorum, topic = sys.argv[1:]
kvs = KafkaUtils.createStream(
ssc,
zkQuorum,
"spark-streaming-consumer", # Consumer Group
{topic: 1} # Topic and Partition
)
lines = kvs.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
运行
$ cd /usr/local/spark/mycode/streaming/kafka/
$ /usr/local/spark/bin/spark-submit \
> ./KafkaWordCount.py localhost:2181 wordsendertest
转换操作
DStream 无状态转换操作
map(func): 对源 DStream 的每个元素, 采用func函数进行转换, 得到一个新的 DStreamflatMap(func): 与 map 相似, 但是每个输入项可用被映射为 0 个或者多个输出项filter(func): 返回一个新的 DStream, 仅包含源 DStream 中满足函数func的项repartition(numPartitions): 通过创建更多或者更少的分区改变 DStream 的并行程度reduce(func): 利用函数func聚集源 DStream 中每个 RDD 的元素, 返回一个包含单元素 RDDs 的新 DStreamcount(): 统计源 DStream 中每个 RDD 的元素数量union(otherStream): 返回一个新的 DStream, 包含源 DStream 和其他 DStream 的元素countByValue(): 应用于元素类型为K的 DStream 上, 返回一个(K, V)键值对类型的新 DStream, 每个键的值是在原 DStream 的每个 RDD 中的出现次数reduceByKey(func, [numTasks]): 当在一个由(K,V)键值对组成的 DStream 上执行该操作时, 返回一个新的由(K,V)键值对组成的 DStream, 每一个 key 的值均由给定的reduce(func)聚集起来join(otherStream, [numTasks]): 当应用于两个 DStream (一个包含(K,V)键值对,一个包含(K,W)键值对) , 返回一个包含 (K, (V, W)) 键值对的新 Dstreamcogroup(otherStream, [numTasks]): 当应用于两个 DStream (一个包含(K,V)键值对,一个包含(K,W)键值对) , 返回一个包含(K, Seq[V], Seq[W])的元组transform(func): 通过对源 DStream 的每个 RDD 应用 RDD-to-RDD 函数, 创建一个新的 DStream. 支持在新的 DStream 中做任何 RDD 操作
DStream 有状态转换操作
滑动窗口转换操作
- 事先设定一个滑动窗口的长度 (也就是窗口的持续时间)
- 设定滑动窗口的时间间隔 (每隔多长时间执行一次计算) , 让窗口按照指定时间间隔在源 DStream 上滑动
- 每次窗口停放的位置上, 都会有一部分 Dstream (或者一部分 RDD) 被框入窗口内, 形成一个小段的 Dstream
- 可以启动对这个小段 DStream 的计算
滑动窗口转换操作 API
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])- 应用到一个
(K,V)键值对组成的 DStream 上时, 会返回一个由(K,V)键值对组成的新的 DStream. 每一个 key 的值均由给定的reduce(func)进行聚合计算. 注意: 在默认情况下, 这个算子利用了 Spark 默认的并发任务数去分组. 可以通过numTasks参数的设置来指定不同的任务数
- 应用到一个
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])- 更加高效的
reduceByKeyAndWindow, 每个窗口的 reduce 值, 是基于先前窗口的 reduce 值进行增量计算得到的; 它会对进入滑动窗口的新数据进行 reduce 操作, 并对离开窗口的老数据进行”逆向 reduce”操作. 但是, 只能用于”可逆 reduce 函数”, 即那些 reduce 函数都有一个对应的”逆向 reduce 函数” (以InvFunc参数传入)
- 更加高效的
#!/usr/bin/env python3
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: WindowedNetworkWordCount.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingWindowedNetworkWordCount")
ssc = StreamingContext(sc, 10)
ssc.checkpoint("file:///usr/local/spark/mycode/streaming/socket/checkpoint")
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)
counts.pprint()
ssc.start()
ssc.awaitTermination()
reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)
updateStateByKey 操作
需要在跨批次之间维护状态时, 就必须使用 updateStateByKey 操作词频统计实例:
对于有状态转换操作而言, 本批次的词频统计, 会在之前批次的词频统计结果的基础上进行不断累加, 所以, 最终统计得到的词频, 是所有批次的单词的总的词频统计结果
NetworkWordCountStateful.py
#!/usr/bin/env python3
from __future__ import print_function
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import sys
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: NetworkWordCountStateful.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")
ssc = StreamingContext(sc, 1)
ssc.checkpoint("file:///usr/local/spark/mycode/streaming/stateful/")
# RDD with initial state (key, value) pairs
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
running_counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.updateStateByKey(updateFunc, initialRDD=initialStateRDD)
running_counts.pprint()
ssc.start()
ssc.awaitTermination()
输出操作
把 DStream 输出到文本文件中
#!/usr/bin/env python3
from __future__ import print_function
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import sys
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
def main():
if len(sys.argv) != 3:
print("Usage: NetworkWordCountStateful.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")
ssc = StreamingContext(sc, 1)
ssc.checkpoint("file:///usr/local/spark/mycode/streaming/stateful/")
# RDD with initial state (key, value) pairs
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
running_counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.updateStateByKey(updateFunc, initialRDD=initialStateRDD)
running_counts.saveAsTextFiles("file:///usr/local/spark/mycode/streaming/stateful/output")
running_counts.pprint()
ssc.start()
ssc.awaitTermination()
if __name__ == "__main__":
main()
把 DStream 写入到 MySQL 数据库中
#!/usr/bin/env python3
from __future__ import print_function
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import sys
import pymysql
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
def dbfunc(records):
db = pymysql.connect("localhost","root","123456","spark")
cursor = db.cursor()
def doinsert(p):
sql = "insert into wordcount(word,count) values ('%s', '%s')" % (str(p[0]), str(p[1]))
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
for item in records:
doinsert(item)
def func(rdd):
repartitionedRDD = rdd.repartition(3)
repartitionedRDD.foreachPartition(dbfunc)
def main():
if len(sys.argv) != 3:
print("Usage: NetworkWordCountStateful <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")
ssc = StreamingContext(sc, 1)
ssc.checkpoint("file:///usr/local/spark/mycode/streaming/stateful")
# RDD with initial state (key, value) pairs
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
running_counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.updateStateByKey(updateFunc, initialRDD=initialStateRDD)
running_counts.pprint()
running_counts.foreachRDD(func)
ssc.start()
ssc.awaitTermination()
if __name__ == "__main__":
main()