- S3 is object-based, it allows to upload files from 0 bytes to 5 TB (object size)
- Files are stored in Buckets
Basics of S3
- S3 is a universal namespace, which means the names should be unique globally.
- for example,
https://s3 ........ amazonaws.com/<bucket_name>, this<bucket_name>should be unique
- for example,
- Once uploading successfully, it will return HTTP Status Code
200
What are objects in S3?
For object in S3, it has the several features.
- Key. this is the FULL path
- eg.
<bucket_url>/somePath/someFolder/filename, heresomePath/someFolder/filenameis the Key, not just thefilename - there are no concept of
"directories"in S3. the key can contain slashes/
- eg.
- Value. content of the body
- max-size is 5TB, if uploading greater than 5GB, then you can use “multi-part uploading”
- VersionID. version control if enabled
- MetaData. list of text key / value pairs - system or user data
- Tags. Unicode key / value pairs (10 most), uesful for security or lifecycle
- Subresources:
- Access Control List
- Torrent
Consistency Model in S3
Basically, changes to object can take a little bit of time to propogate.
Read After Write
If you write a new file and read it immediately afterwards, you will be able to view that file
Eventually Consistent
If you update AN EXISTING file or DELETE a file, then read it immediately, you may get the older version or you may not. But if you wait for a minute, you will get the latest version.
PUTs of new objects have a read after write consistency. DELETEs and overwrite PUTs have eventual consistency across S3
S3 Features
- Tiered Storage Available
- Lifecycle Management
- Versioning
- Encryption
- MFA Delete
- Secure your data using
- Access Control List
- Bucket Policy
S3 Storage Classes
https://aws.amazon.com/s3/storage-classes/
There are several classes for S3 storage
| Storage Tiers | Description |
|---|---|
| S3 Standard | This tier provides 99.99% availability and 99.999999999% durability (there are 11 9s LOL) |
| S3 - IA (Infrequently Accessed) | Data that is accessed less frequently, but requires rapid access. Lower fee than S3 - Standard. but it charge for a retrieval fee |
| S3 One Zone - IA | This does not require multiple availability zone data resilience |
| S3 - Intelligent Tiering | This tier utilizes Machine Learning |
| S3 - Glacier | For data archive |
| S3 - Glacier Deep Archive | Slowest, cheapest. File retrieval time ~ 12 hours |
- Durability across all storage classes are the same 11 9’s
- Availability for Standard is 99.99%, for S3-IA is 99.9%
Glacier & Glacier Deep Archive
Glacier has 3 options to retrieve objects
- Expedited: 1 ~ 5 minutes
- Standard: 3 ~ 5 hours
- Bulk: 5 ~ 12 hours
- Minimum storage duration of 90 days
Glacier Deep Archive - for long term storage, cheaper even
- Standard: 12 hours
- Bulk: 48 hours
- Minimum storage duration of 180 days
First byte latency
- milliseconds for S3 Standard, S3-IA, S3-Intelligent Tiering
- select minutes or hours for S3 Glacier
- select hours for S3 Glacier Deep Archive
S3 Security
- User based
- IAM policies - which API calls should be allowed for a specific user from IAM console
- Resource based
- Bucket policies - bucket wide rules from the S3 console - allows cross account
- Object Access Control List - Finer Grain
- Bucket Access Control List - Less Common
S3 Bucket Policies
JSON based policies
- Resources: buckets and objects
- Actions: set of API to allow or deny
- Effect: allow or deny
- Principal: the account or user to apply the policy to
S3 bucket for policy to
- grant public access to the bucket
- force objects to be encrypted at upload
- grant access to another account (Cross-Account)
S3 Security - Other
Networking
Supports VPC Endpoints (for instances, in VPC without www internet)
Logging an Audit
- S3 access logs can be stored in other S3 bucket
- API calls can be logged in AWS CloudTrail
User Security
- MFA
- Signed Urls: URLs that are valid only for a limited time (eg: premium video service for logged in users)
S3 Encryption
All of the new files that are uploaded to S3 buckets are PRIVATE
There are three encryption methods:
- Encryption In Transit
- SSL / TLS
- Encryption At Rest
- S3 Managed Keys :
SSE-S3 - AWS Key Management Service, Managed keys :
SSE-KMS - Server-side Encryption with Customer Provided keys :
SSE-C
- S3 Managed Keys :
- Client Side Encryption, like gpg, etc.

SSE-S3
The encryption using keys handled & managed by AWS S3, the files are encrypted at server-side.
SSE-S3 use AES-256 as encryption type, also "x-amz-server-side-encryption":"AES256" must be set in the request header
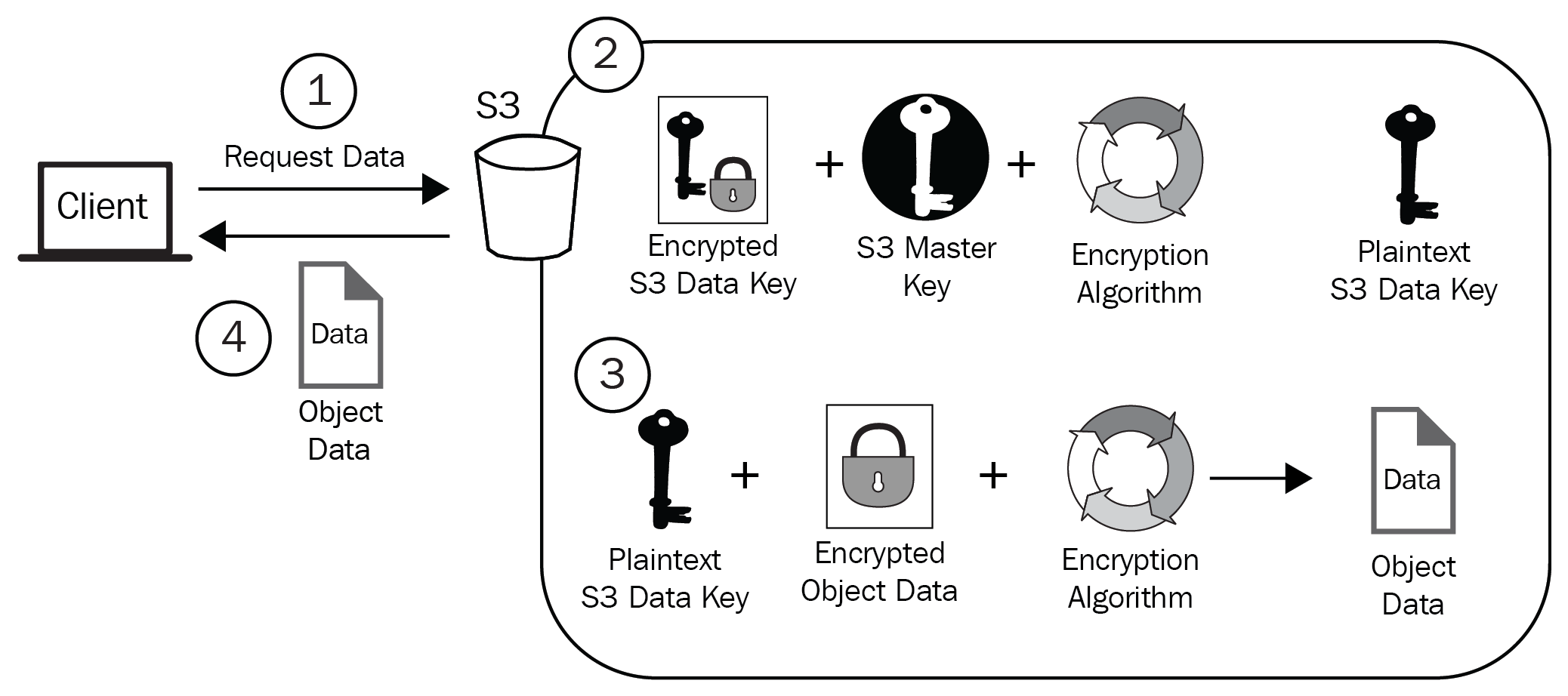
This diagram shows the three-step encryption process when using SSE-S3:

- The client selects their object(s) to upload to S3 and indicates the encryption mechanism of SSE-S3 during this process.
- S3 then takes control of the object and encrypts it with a plaintext data key generated by S3. The result is an encrypted version of the object, which is then stored in your chosen S3 bucket.
- The plaintext data key that is used to encrypt the object is then encrypted with an S3 master key, resulting in an encrypted version of the key. This now-encrypted key is also stored in S3 and is associated with the encrypted data object. Finally, the plaintext data key is removed from memory in S3.
This diagram shows the four-step decryption process when using SSE-S3:
SSE-KMS

The encryption using keys handled & managed by AWS KMS, the files are encrypted at server-side.
"x-amz-server-side-encryption":"aws:kms"
advantages:
- user control
- audit trail
SSE-C

- Server side encryption using data keys full managed by the customer outside of AWS
- S3 does not store encryption key
- HTTPS must be used
Encryption In Transit
AWS S3 exposes:
- HTTP endpoint: non-encrypted
- HTTPS endpoint: encryption in flight (recommended)
HTTPS is mandatory for SSE-C
S3 Versioning
S3 also supports version control, it is enabled at bucket level
- Stores all versions of an object, inclusding all writes and even if you delete a object. For delete operation, it is a
deletemarker. but you can see the file when theversionis toggled on (reason see below) - Backup tool
- Once enabled, cannot be disenabled, but you can
suspend - Integrates with Lifecycle rules
- Support MFA
any file that is not versioned prior to enabling versioning will have version
"null"
Suppose the v1 version of your file is 100 KB, and you edited it to 200 KB. You upload the file again to S3. Then this file will be version 2, but the size will be 300 KB, since the size of file is accumulated
Delete Marker
https://docs.aws.amazon.com/AmazonS3/latest/dev/DeleteMarker.html
AWS create Delete Marker, it does so whenever you send a DELETE Object request on an object in a versioning-enabled or suspended bucket. The object named in the DELETE request is not actually deleted. Instead, the delete marker becomes the current version of the object. (The object’s key name (or key) becomes the key of the delete marker.)
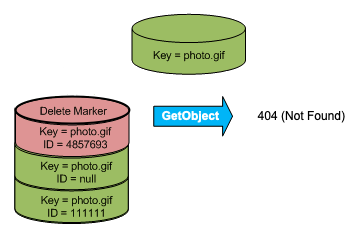
If you try to get an object and its current version is a delete marker, Amazon S3 responds with:
- A
404(Object not found) error - A response header,
x-amz-delete-marker: true
The response header tells you that the object accessed was a delete marker. This response header never returns false; if the value is false, Amazon S3 does not include this response header in the response.
The following figure shows how a simple GET on an object, whose current version is a delete marker, returns a 404 No Object Found error.
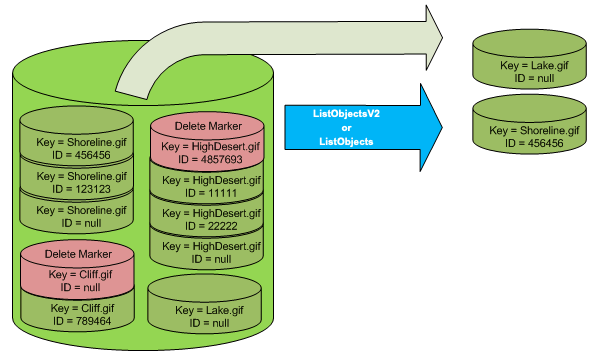
The only way to list delete markers (and other versions of an object) is by using the versions subresource in a GET Bucket versions request. A simple GET does not retrieve delete marker objects. The following figure shows that a GET Bucket request does not return objects whose current version is a delete marker.
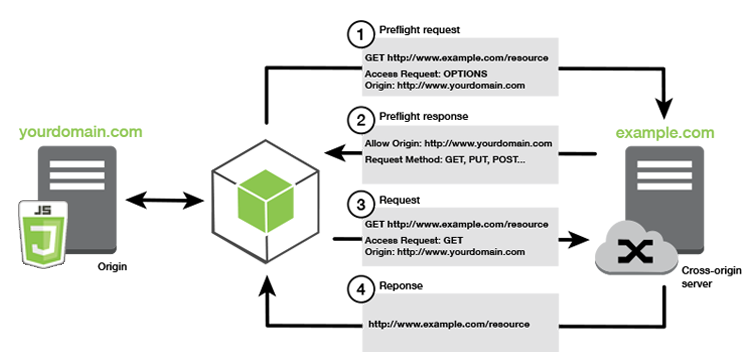
S3 CORS
If you request data from another S3 bucket, you need to enable CORS
Cross Origin Resource Sharing (CORS) allows you to limit the number of websites that can request your files in S3 and limit your costs
Lifecycle Management with S3
S3 uses lifecycle rules to manage objects
- Automates moving your objects between different storage tiers
- It can be used in conjection with versioning
- It can be applied to current versions and previous versions
S3 Lifecycle Rules
There are two types of actions in S3 Lifecycle Rules
- Transition actions: it defines when objects are transitioned to another storage class
- move object to Standard IA class 60 days after creation
- move to glacier for crchiving after 6 months
- Expiration actions: it configures objects to expire/delete after some time
- access log files can be set to delete after 365 days
- delete old version files
- delete incompleted multi-part uploads
The rules can be applied for a certain prefix (s3://<bucket_name>/mp3/*) or certain objects tags
Cross Region Replication in S3
Cross Region Replication in S3 requires enabling versioning for both source bucket and destination bucket

The buckets (source and destination) must be in different AWS Regions. It can cross different accounts. The copy is async.
Keypoints of Cross Region Replication:
- if you put delete marker in original bucket, it will not replicate the delte marker in CRR Bucket
- the files already in the source bucket will not be replicated automatically
- Versioning should be enabled both in source and destination bucket
- Regions must be unique (LOL)
- Files in an existing bucket are not replicated automatically
- Delete markers are not replicated
- Delete individual versions / delete markers will not be replicated
S3 MFA-Delete
MFA forces user to generate a code on a device (usually a mobile phone or hardware) before doing important operations on S3
In order to use MFA-Delete feature, you need to enale Versioning on the S3 bucket, later, you will need MFA to:
- permanently delete an object version
- suspend Versioning on the bucket
Only the bukcet owner (root account) can enable/disable MFA-Delete feature, and it currently can only be enabled using CLI
S3 Access Logs
You can log all access to S3 buckets, any requests made to S3, from any accounts, whatever authorized or denied, will be logged into another S3 bucket (two S3 buckets here, one is the bucket we wanna monitor the requests, and another is the bucket where logs are stored in)
We can use Athena to analyze the logs
S3 Pre-signed Urls
S3 Pre-signed Urls can be generated via SDK or CLI
- downloading: we can use CLI
- uploading: we must use SDK
1
2
3
4
5
6
# set signature version, for files are encrypted, otherwise you will have issues
$ aws configure set default.s3.signature_version s3v4
# create a pre-signed url which lasts for 5 minutes. don't forget to add region in the command
# --expires-in option default value is 3600 seconds
$ aws s3 presign s3://<bucket_name>/<filename> --expires-in 300 --region us-east-1a
Users given a pre-signed url will inherit the permissions of the person who generated the url for GET / PUT
Example usage case:
- only logged-in user can download a premium video on your S3 bucket
- allow an ever changing list of users to download files by generating URLs dynamically
S3 Performance Baseline
at least
- 3500 PUT / COPY / POST / DELETE
- 5500 GET / HEAD
requests per second per prefix in a bucket, there are no limits to the number of prefixes in a bucket
what is a prefix ?
suppose you have a file with full path like this:
<bukcet_name>/folder1/sub1/filethen the prefix will be
/folder1/sub1/
if you spread reads across all four prefixes evenly, you can achieve 22000 requests per second for GET and HEAD
S3 - KMS Limitation
If you use SSE-KMS, then you may be impacted by the KMS limits, since
- when you upload a file, it will call the
GenerateDataKeyAPI during the call to KMS API - when you download a SSE-KMS encrypted file, it will cal the
DecryptKMS API
since API calls will have a upper bound, then your performance with S3 will be impacted
Improve S3 Performance
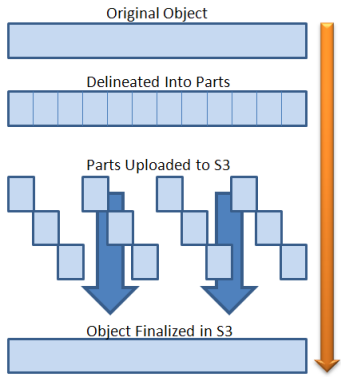
Multi-part upload
Multipart upload is a three-step process: You initiate the upload, you upload the object parts, and after you have uploaded all the parts, you complete the multipart upload. Upon receiving the complete multipart upload request, Amazon S3 constructs the object from the uploaded parts, and you can then access the object just as you would any other object in your bucket.
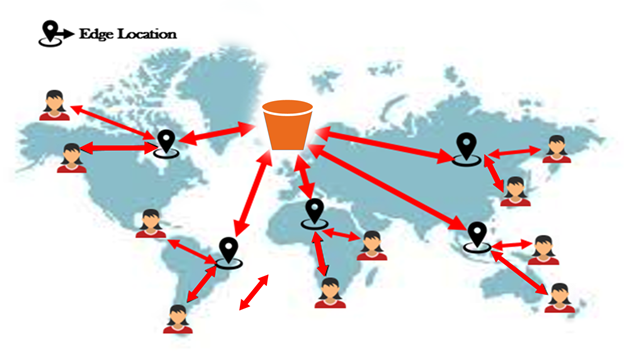
S3 Transfer Acceleration (upload only)
This utilizes the CloudFront Edge Networks to accelerate your uploads to S3. Instead of uploading directly to your S3 bucket, you can use a distinct url to upload directly to an Edge Location, which will then transfer to S3 using Amazon Backbone Network
This is compatible with multi-part upload
S3 Performance - S3 Byte-Range Fetches
Parallelize GET’s by requesting specific byte ranges, better resilience in case of failures
You can fetch a byte-range from an object, transferring only the specified portion.
Typical sizes for byte-range requests are 8 MB or 16 MB. If objects are PUT using a multipart upload, it’s a good practice to GET them in the same part sizes (or at least aligned to part boundaries) for best performance. GET requests can directly address individual parts; for example, GET ?partNumber=N.
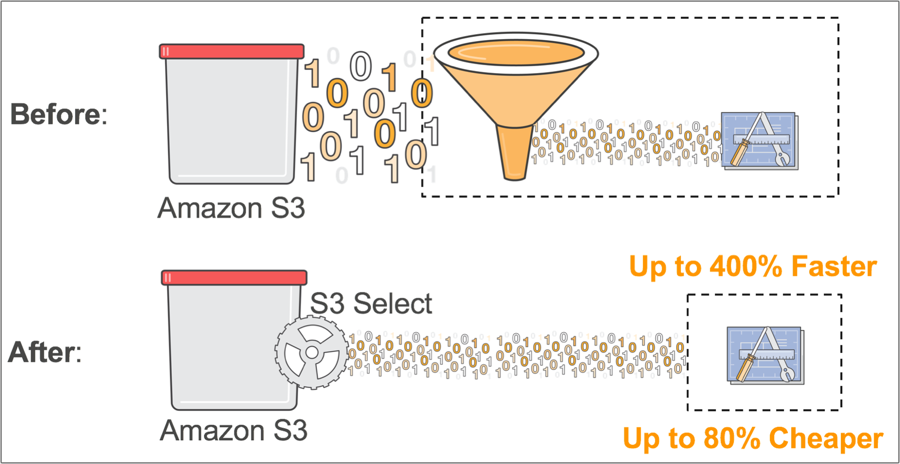
S3 Select & Glacier Select
With usage of S3 Select or Glacier Select, you can retrieve less data using SQL by performing server side filtering, which can be filter by row / columnes.
S3 Object Lock & Glacier Vault Lock
| S3 Object Lock | Glacier Vault Lock |
|---|---|
| Adopt a WORM (Write-once, Read-many) model | Adopt a WORM (Write-once, Read-many) model |
| Block an object version deletion for a specific amount of time | Local the policy for future edits (can no longer be changed) |
| Helpful for compliance and data retention |
AWS Athena
- Athena is a Serverless service to perform analytics directly against S3 files.
- We can use SQL to do queries, it also has JDBC / ODBC driver
- It charged per query and amount of data scanned
In the exam, if it asks to "analyze data directly on S3", we should use Athena
Amazon CloudFront
CloudFront is a Content Delievery Network (CDN), which is:
a system of distributed servers / network that deliever webpages and other web content to a user based on the geographic locations of the user, origin of the webpage and a CDN.
- it improves read performance, content is cached at Edge Locations
- it has DDoS protention, integration with AWS Shield
Key Terminology of CloudFront
Edge Location
This is the location where content will be cached, and separate to the AWS Region / AZ.
Origin
This is the origin of all the files that the CDN will distribute. This can be an
- S3 Bucket
- for distributing files and caching them at the edge locations
- enhanced security with CloudFront Origin Access Identity (OAI)
- CloudFront can be used as an ingress (to upload files to S3)
- S3 Website
- must first enable the bucket as a static S3 website
- Cutom Origin (HHTP) - must be publicly accessible
- EC2 Instance
- Elastic Load Balancer
- Route53
Distribution
This is the name given the CDN which consists of a collection of Edge Locations
There are two types of distribution
- Web Distribution: for website
- RTMP: for Media Streaming
- Edge Location are not just
READonly - you can also write to it, since files are cached here - Objects are cached for the life of the TTL (Time To Live)
- You can clear cached objects (Invalidate the cache), but you will be charged
- CloudFront also supports "Restrict Viewer Access", like contents can only be viewed by "paid" users. using "Signed Urls"
CloudFront Signed URL & Signed Cookies
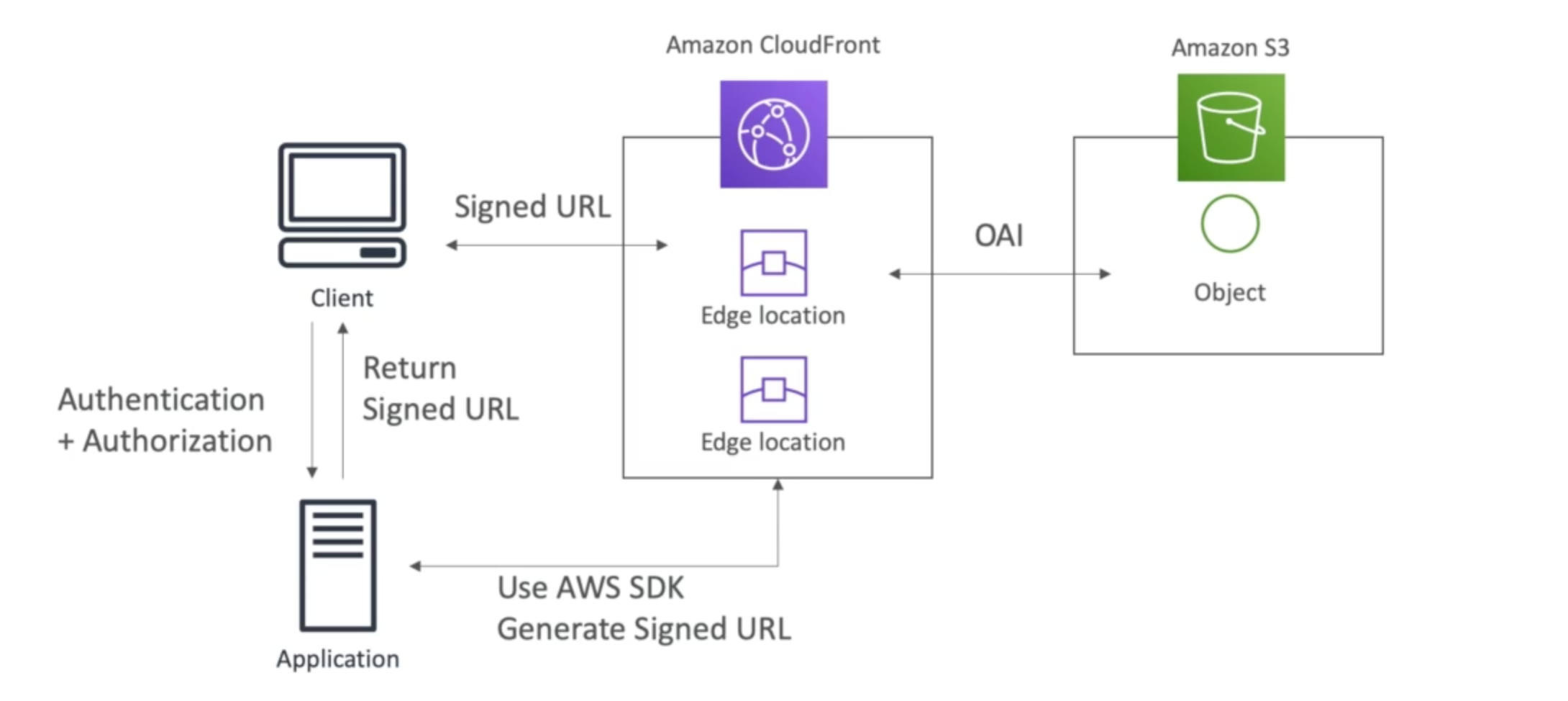
It will be suitable if you want to distribute paid shared content to premium users over the world, with CloudFront Signed URL / Cookie, we attach a policy with:
- URL expiration
- IP ranges to be allowed to access the data
- trusted signers - which AWS account can create signed urls
Signed URL : access to individual files (one signed URL per file)
Signed Cookies : access to multiple files (one signed cookie for many files)
How long should the URL be valid for ?
- shared content (movie & music): make it short
- private content (private to users): you can make it last for years
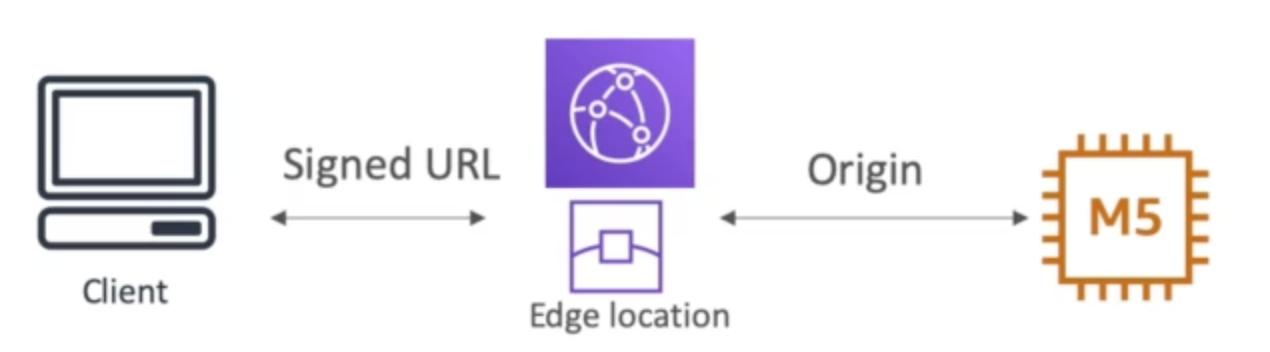
CloudFront Signed URL vs S3 Pre-Signed URL
| CloudFront Signed URL | S3 Pre-Signed URL |
|---|---|
| allow access to a path, no matter the origin | issue a request as the person who pre-signed the URL |
| acocount wide key-pair, but only the root user can manage it | use the IAM key of the signing IAM principal |
| can be filtered by IP, path, date, expiration | limited lifetime |
| can leverage caching features | |
 |  |
CoudFront Geo Restriction
- You can restrict who can access your distribution
- Allowlist: allow your users to access your content only if they are in one of the areas on a list of approved area
- Blocklist: Prevent your users from accessing your content if they are in ….
This can be a good use case when copyright laws to control access to content
CloudFront vs S3 cross Region Replication
| CloudFront | S3 Cross Region Replication |
|---|---|
| Global Edge Network | must be setup for each Region you want replication to happen |
| Files are cached for a TTL (maybe a day) | Files are updated in near real-time |
| Great for static content that myst be available everywhere | Read Only |
| Great for dynamic content that needs to be available at low-latency in few regions |
AWS Global Accelerator
This utilizes the AWS internal network to route to your application. there will be 2 Anycast IPs created for your app
the traffic flow will be:
1
Anycast IP -> Edge Location -> Your application
What is Unicast IP and Anycast IP ?
Unicast IP : one server holds one IP address
Anycast IP : all servers hold the same IP address and the client is routed to the nearest one
AWS Global Accelerator works with Elastic IP, EC2 Instances, ALB, NLB (puclic or private one)
It has:
- Consistent Performance
- Intelligent routing to lowest latency and fast regional failover
- No issue with client cache (IP dont change)
- Internal AWS Network - fast
- Health Checks
- Global Accelerator performs a health check of you applications
- helps make the app global (failover less than 1 minute for unhealthy)
- disaster recovery
- Security
- only 2 external IP need to be allowlisted
- DDoS protection <- AWS Shield
AWS Global Accelerator vs CloudFront
They both user AWS global network and edge location to accelerate, also they both integrate with AWS Shield for DDoS Protection
However,
CloudFront
- improves performance for cacheable content (such as images and videos)
- dynamic content (such as API acceleration and dynamic site delievery)
- content is served at the edge location
Global Accelerate
- improves performance for a wide range of applications over TCP or UDP
- proxying packets at the edge location to applications running in one or more AWS Regions
- good fit for non-HTTP use cases
- HTTP cases: which requires static IP addresses, or deterministic, fast regional failover
Performance across the S3 Storage Classes
| S3 Standard | S3 Intelligent-Tiering* | S3 Standard-IA | S3 One Zone-IA† | S3 Glacier | S3 Glacier Deep Archive | |
|---|---|---|---|---|---|---|
| Designed for durability | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) | 99.999999999% (11 9’s) |
| Designed for availability | 99.99% | 99.9% | 99.9% | 99.5% | 99.99% | 99.99% |
| Availability SLA | 99.9% | 99% | 99% | 99% | 99.9% | 99.9% |
| Availability Zones | ≥3 | ≥3 | ≥3 | 1 | ≥3 | ≥3 |
| Minimum capacity charge per object | N/A | N/A | 128KB | 128KB | 40KB | 40KB |
| Minimum storage duration charge | N/A | 30 days | 30 days | 30 days | 90 days | 180 days |
| Retrieval fee | N/A | N/A | per GB retrieved | per GB retrieved | per GB retrieved | per GB retrieved |
| First byte latency | milliseconds | milliseconds | milliseconds | milliseconds | select minutes or hours | select hours |
| Storage type | Object | Object | Object | Object | Object | Object |
| Lifecycle transitions | Yes | Yes | Yes | Yes | Yes | Yes |
† Because S3 One Zone-IA stores data in a single AWS Availability Zone, data stored in this storage class will be lost in the event of Availability Zone destruction.
* S3 Intelligent-Tiering charges a small tiering fee and has a minimum eligible object size of 128KB for auto-tiering. Smaller objects may be stored but will always be charged at the Frequent Access tier rates. See the Amazon S3 Pricing for more information.
** Standard retrievals in archive access tier and deep archive access tier are free. Using the S3 console, you can pay for expedited retrievals if you need faster access to your data from the archive access tiers.
*** S3 Intelligent-Tiering first byte latency for frequent and infrequent access tier is milliseconds access time, and the archive access and deep archive access tiers first byte latency is minutes or hours.